

How Facebook created the largest Memcached system in the world
How Facebook created the largest Memcached system in the world
Facebook handled billions of requests per second efficiently
Facebook receives billions of requests per second and stores trillions of items in their databases.
According to their team, “traditional web architectures” just couldn’t keep up with the social network’s demands.1
Facebook used a simple key-value store called Memcached and scaled it to efficiently handle billions of requests per second for trillions of items.
They noted in 2013 that their system was “the largest memcached installation in the world”.2
If you want to skip the technical portion, feel free to skip to the Lessons and Takeaways section at the end.
Facebook’s Rules for Scaling
Focus on the user. Any change must only impact a user facing or operational issue.
Don’t chase perfection. They’re fine with some users getting stale data if it means they can scale further.
How Facebook Scaled
Requirements
They kept the following assumptions in mind:
Users read more than they write.
There are multiple data sources to read from.
They need reading, writing, and communications to happen almost instantaneously.
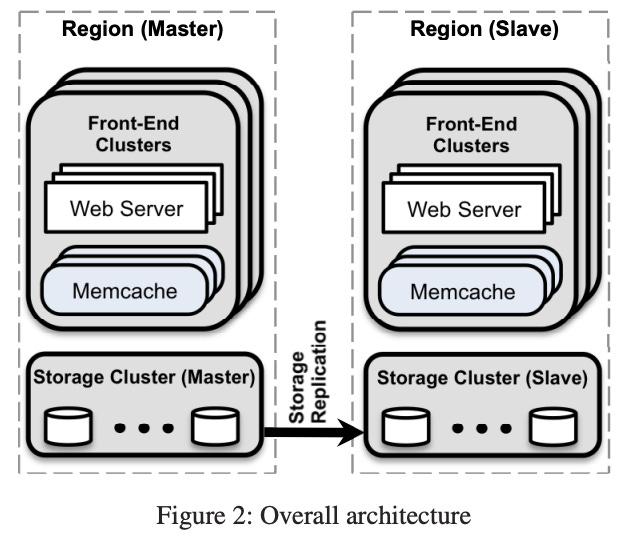
They had 3 layers of scaling: cluster, region, and worldwide.
They scaled Memcached to do this.
Memcached explained quickly
It’s a basic key value store, implemented using a hash table, stored in-memory. It’s a caching layer over the database.
Database reads are much more expensive than in-memory reads. Facebook’s databases stored trillions of items.
For example, in an app I developed, a 1.2MB JSON response took ~1100ms to return. After I installed Memcached, it only took 200ms to return when cached.
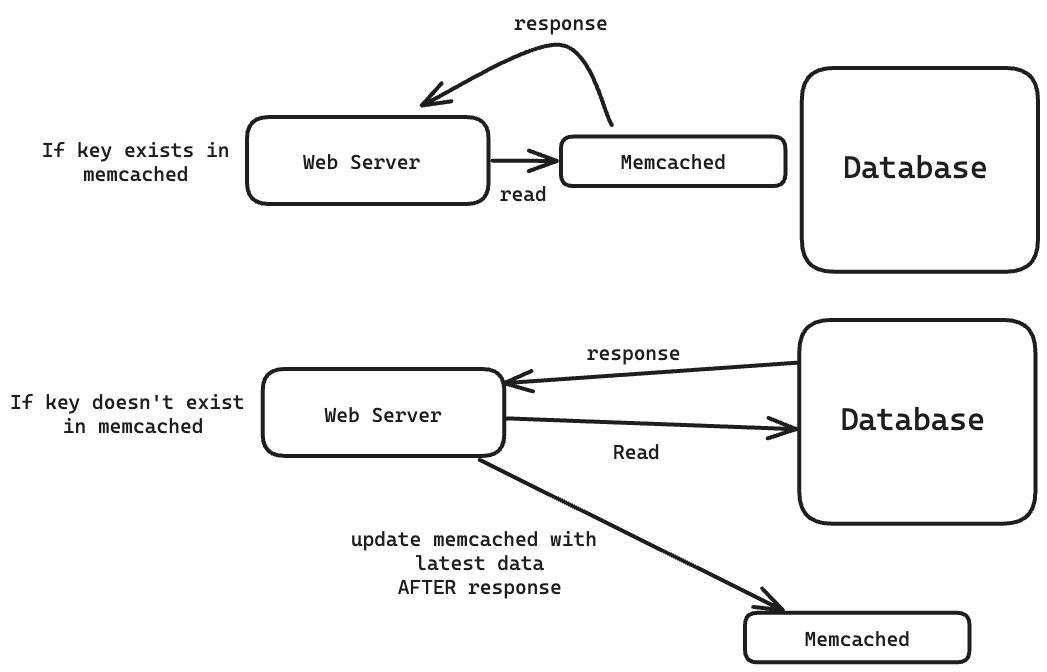
What Facebook stored in Memcached
Memcached stored responses to various requests.
If a user requested their profile information, and it hadn’t changed since their last request, that request’s response was stored in Memcached already.
It also stored common intermediate artifacts, such as pre-computed results from Facebook’s machine learning algorithms.
Why Memcached?
“Memcached provides a simple set of operations (set, get, and delete) that makes it attractive as an elemental component in a large-scale distributed system.” (Section 2, Overview)
In the paper, they use Memcached as the basic key-value store, and Memcache as the distributed system version of Memcached that they’re running. This distributed version of Memcached has extra abilities, like a special client for server-to-server communication and more.
I found their naming confusing, so I’ll refer to their distributed system version, memcache, for the rest of this post.
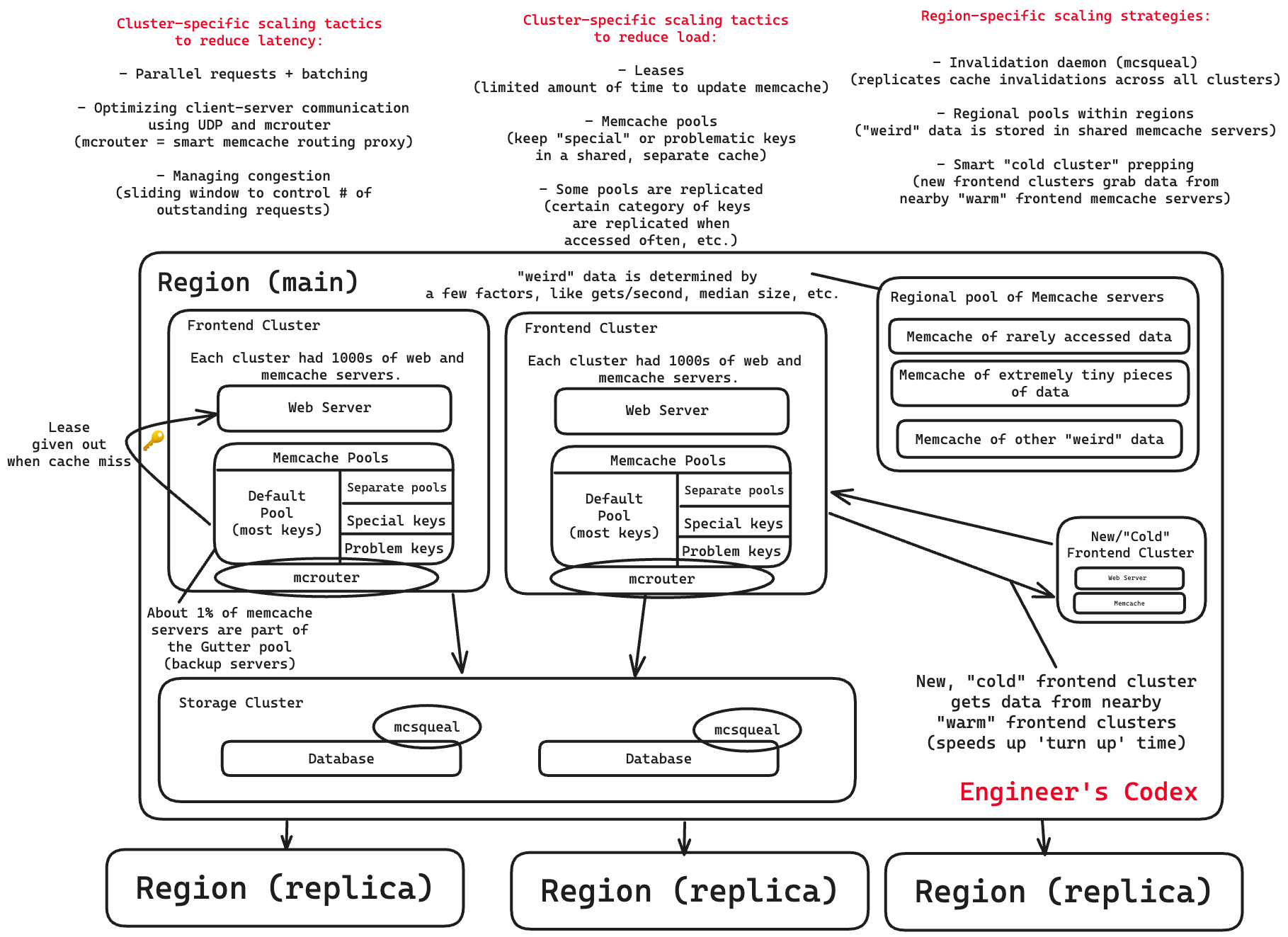
Cluster Scaling
Goals:
Reduce latency of reading data
Reduce database load from reading data
Within a cluster, Facebook had thousands of servers.
Each server had a memcache client, which served a range of functions (compression, serialization, compression, etc). All clients had a map of all available servers.
Loading a popular Facebook page results in an average of 521 distinct reads from memcache.
One web server usually will have to communicate with multiple memcache servers just for 1 request.
Reducing latency
Requests had to be completed and returned in a near real-time fashion.
Facebook had three strategies: parallel requests + batching, faster client-server communication, and controlling request congestion.
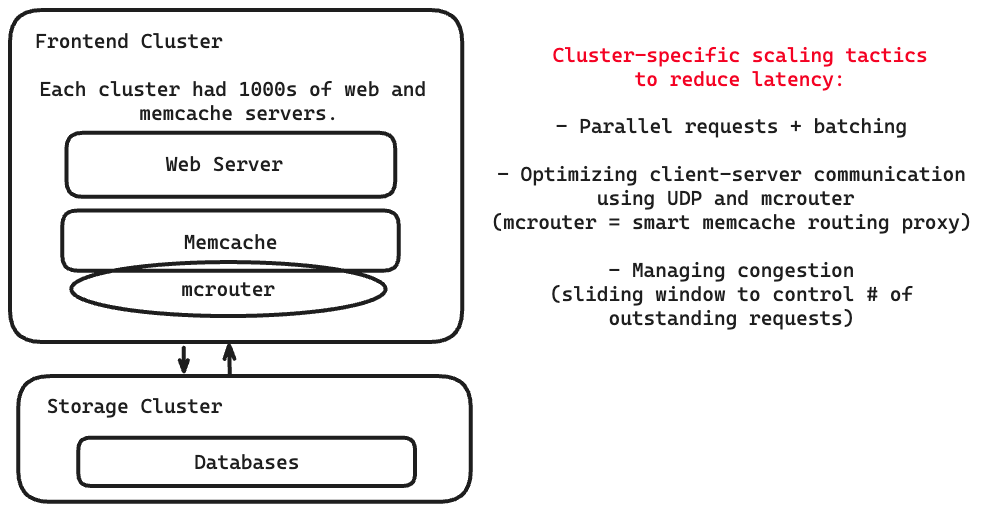
Parallel requests and batching
The goal of using parallel requests and batching was to reduce the number of network round trips.
They created a DAG of data dependencies that was used to maximize the number of items that can be fetched at a time, which was 24 keys at a time (on average).
Optimizing client-server communication
Complexity was put into a stateless client so that the memcache servers could be kept simple.
UDP was used for get requests to memcache because any issues are shown as client-side errors. (so the user just tries again)
TCP was used for set/delete operations using an mcrouter instance.
Mcrouter is a proxy that presents the memcache server interface and routes the requests/replies to/from other servers.
Managing congestion
When there are too many requests at once, memcache clients will use a sliding window mechanism to control the number of outstanding requests.
The window size they used was figured out by some data analysis, where they found a balance between too high user latency or too many incoming requests at once
Reducing load on the database
Facebook reduced load on the database with three strategies: leases, memcache pools, and replication within pools.
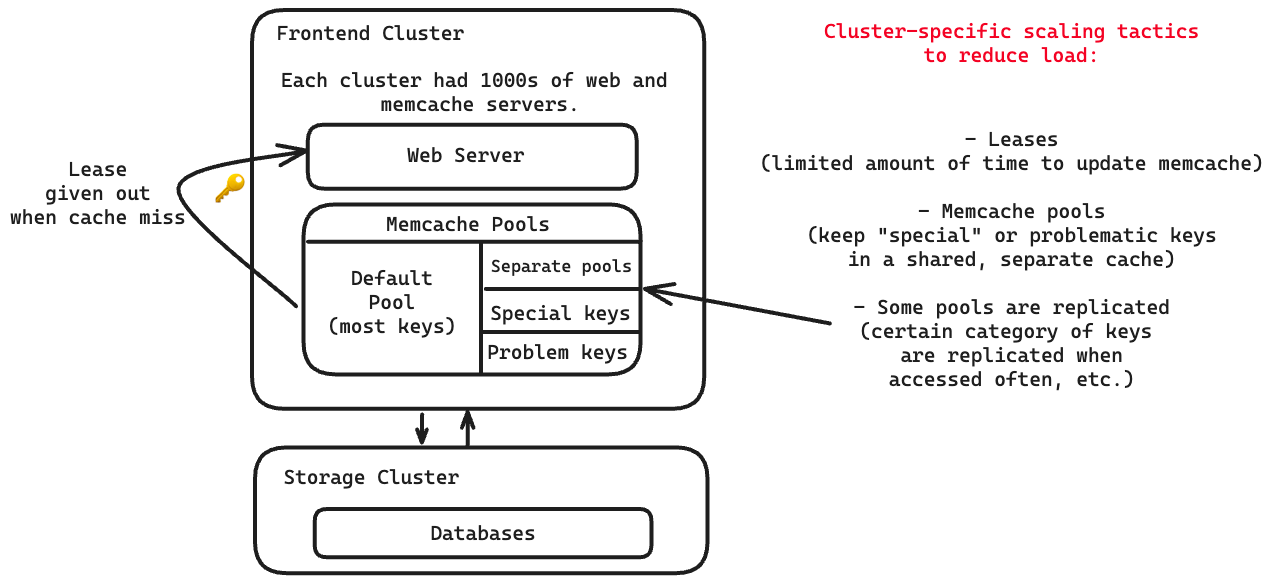
Leases
When the client experiences a cache miss, a memcache instance gives out a temporary lease. Sometimes, when the server writes back to the cache, the lease has expired, meaning it’s too old at that point and has been filled by more recent data.
Leases solved two problems:
stale sets (web server sets a value in distributed memcached that is incorrect)
thundering herds (a key has heavy read and writes activity all at once)
Leases can only be given out once every 10 seconds per key.
Leases allowed the peak database query rate to go from 17K/s to 1.3K/s.
Memcache pools
A cluster’s memcache servers are partitioned into separate pools.
There is one default pool for most keys.
The rest have “problematic” or “special” keys that are not in the default pool, such as keys that are accessed frequently but a cache miss doesn’t matter load or latency wise.
Replication within pools
We choose to replicate a category of keys within a pool when:
(1) the application routinely fetches many keys simultaneously
(2) the entire data set fits in one or two memcache servers
(3) the request rate is much higher than what a single server can manage.
Quoted from Section 3.2.3
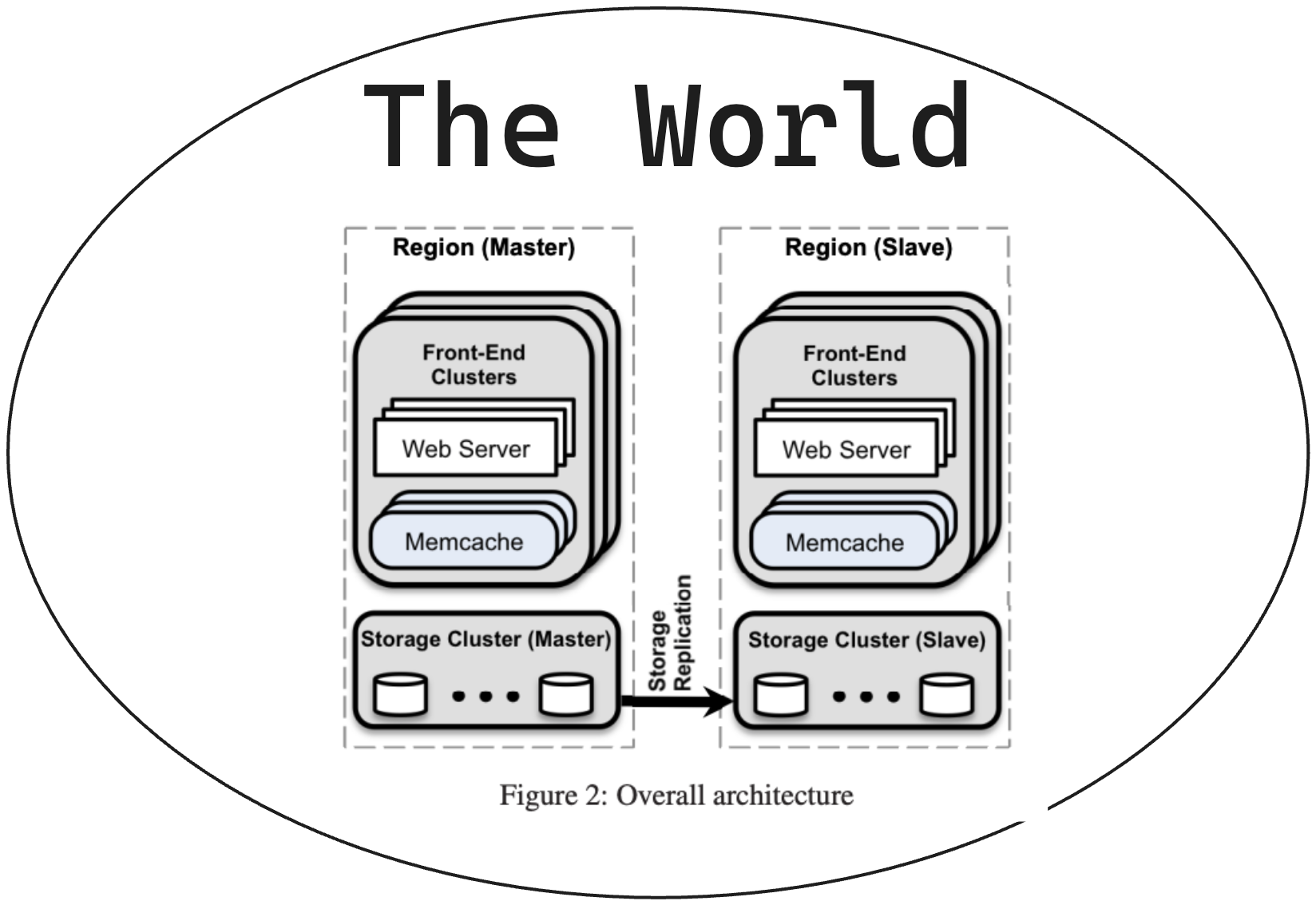
Region Scaling
You can’t scale a cluster infinitely.
Multiple (frontend) clusters form a region. They would have multiple web and memcache servers, along with a storage cluster.
They had three strategies to scale Memcache within a region: an invalidation daemon, a regional pool, and a “cold start” mechanism to spin up new clusters quickly.
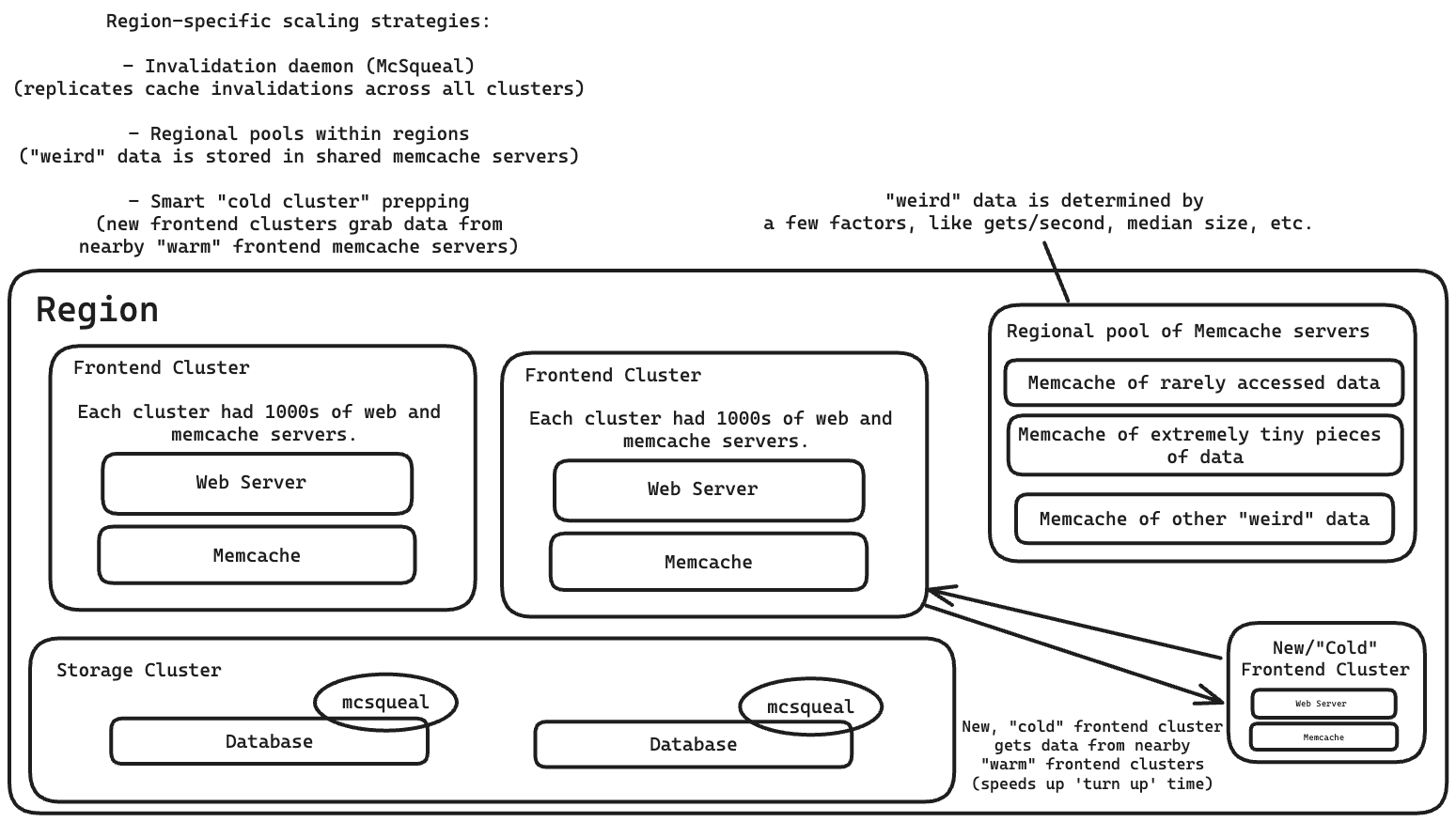
Invalidation Daemon
An invalidation daemon (called mcsqueal) that replicates the cache invalidations across all caches in a region.
When data in the storage cluster (databases) change, it sends invalidations to its own clusters.
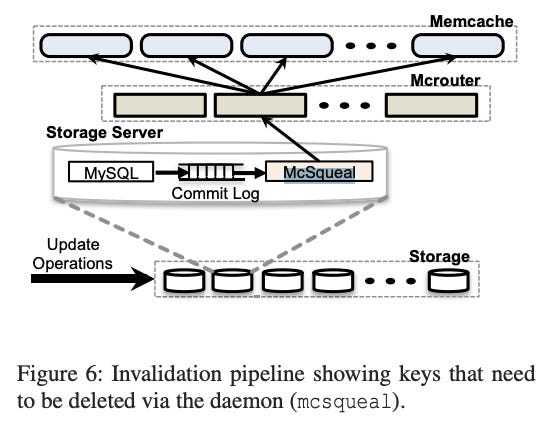
Every database has mcsqueal.
Mcsqueal batches deletes into fewer packets, then sends them to mcrouter servers in each frontend cluster, which then route invalidations to the right Memcache servers.
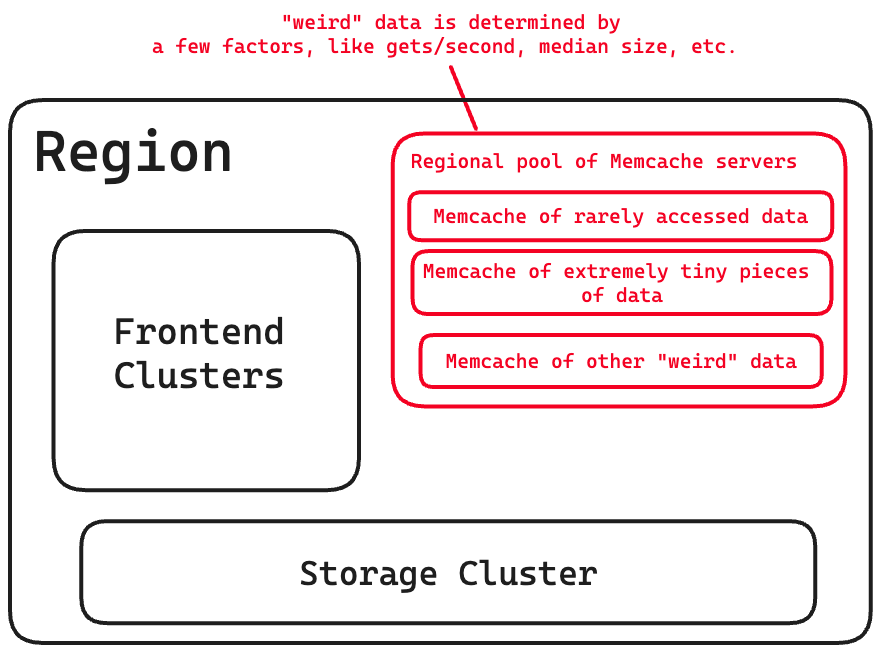
Regional pools within regions
Regional pool of Memcache servers that all clusters in a region share for certain types of data.
Multiple frontend clusters share the same set of Memcache servers, that exist within a region.
Replication is expensive, so the regional pool stores “weird” data, like data that is not accessed often. This is done by using a few factors like median number of users, gets per second, and median value size.
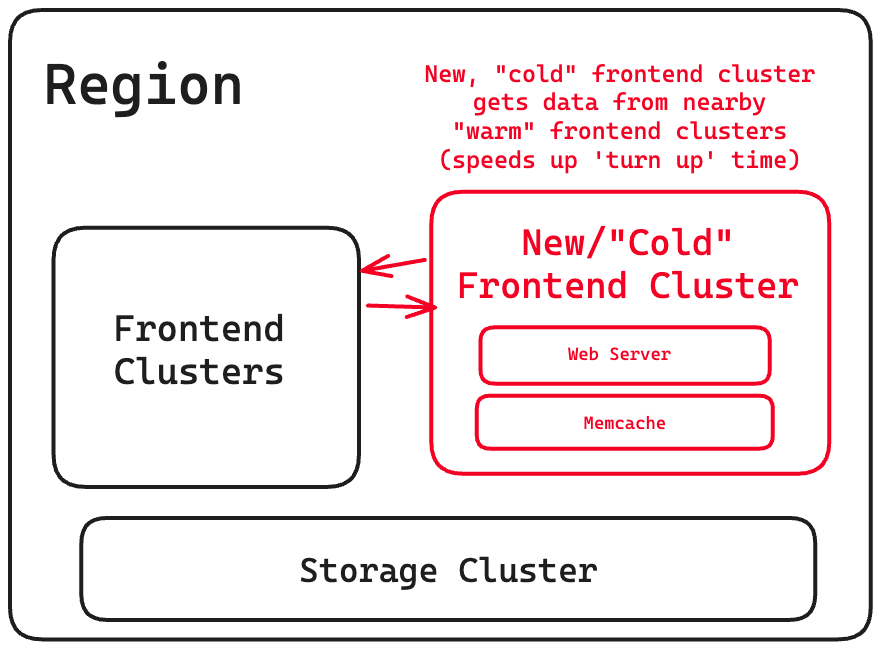
Cold Cluster Prepping
A “cold cluster,” or a frontend cluster with an empty cache, retrieves data from a “warm cluster” or a cluster with normal hit rate caches.
This reduced “turnup time” of a new cluster from few days to just a few hours.
Note: there can be race conditions here with cache consistency, which they solve by adding a two second hold-off to deletes in the cold cluster. This is turned off once the cold cluster’s cache hit rate diminishes.
Worldwide Scaling
Regions are placed around the world for multiple reasons:
be closer to users
mitigate effects of natural events like power failures
some locations have better economic incentives (cheaper power, tax breaks, etc).
Across regions, one region has a storage cluster and several frontend clusters.
One region holds the master databases and the other regions contain read-only replicas, which is done using MySQL’s replication mechanism.
They have best-effort eventual consistency, but emphasize performance and uptime.
Facebook’s team implemented the invalidation daemon mcsqueal after scaling to multiple regions, so they could write code to properly handle planet-scale race conditions right off the bat.
They use a remote marker mechanism to lower probability of reading stale data, which is higher when writes happen from a non-master region. Read more about it from the paper.
Miscellaneous Performance Optimizations
They optimized memcached itself:
Allowed automatic expansion of the internal hash table
Made the server multi-threaded using a global lock
Gave each thread its own UDP port
The first 2 optimizations were given back to the open source community
They also have many more optimizations that stay internal to Facebook.
Software upgrades to a set of memcached servers can take over 12 hours.
They modified memcached to store cached values and other data structures in shared memory regions, so that there’s minimal disruption and downtime.
Handling Failures
At Facebook’s scale, they have servers, hard drives, and other hardware components failing every minute.
When hosts are inaccessible, they have an automated remediation system.
About 1% of memcache servers in a cluster are part of the Gutter pool, and are dedicated to take place of some failed servers.
Overall Architecture
Takeaways and Lessons
First, the lessons by Facebook themselves, found in Section 9 (Conclusion).
(1) Separating cache and persistent storage systems allows us to independently scale them.
(2) Features that improve monitoring, debugging and operational efficiency are as important as performance.
(3) Managing stateful components is operationally more complex than stateless ones. As a result keeping logic in a stateless client helps iterate on features and minimize disruption.
(4) The system must support gradual rollout and rollback of new features even if it leads to temporary heterogeneity of feature sets.
(5) Simplicity is vital.
Takeaways
They prioritized uptime and availability. Each tradeoff they took was explored, measured, and explained well.
Simplicity is vital which also was Instagram engineering’s guiding principle for their own architecture as they scaled.
Simplicity allows them to scale quickly, onboard new engineers, and keep their processes pain free.
They scaled with a proven technology for a very long time. I noticed that they customized memcached for their needs, rather than build their own custom KV store right away.
I don’t believe they use memcached anymore in this way, but, interestingly, this seems like a very different approach to Google or Apple, who prefer building their own custom tools in-house.
I wonder if this helps in onboarding and recruiting. Most backend engineers are familiar with memcached, so it’s easy to understand how it works.
Even back then, they contributed to the research community. This may not be as novel now, but this was quite a contribution back then!
Facebook also contributed some of their changes to the open-source memcached. Open source culture was alive and well in Facebook back then, and it still remains strong today, with React, LLaMA, PyTorch, and more.
I don’t know if Facebook uses Memcached anymore, since this paper about TAO describes a custom-built system that replaces parts of it.
Source: Scaling Memcache at Facebook (2013)
Section 1, Introduction.
Section 1, Introduction
This was very in-depth and informative, Leonardo. Loved the diagrams as well as usual.
My only feedback would be that it may be nice to split an article like this into 2 parts, since there is a lot of ground to cover in one, and I think I'd remember it easier. Still, it's apparent you put a lot of time and effort into this to be exhaustive and give really in-depth takeaways which I love